
Google vient de dévoiler un nouveau venu dans sa gamme de modèles Gemini 2.5 : Flash-Lite. Disponible en préversion, ce modèle mise tout sur la vitesse et le coût réduit, sans sacrifier totalement les performances. Il s’adresse avant tout aux développeurs qui ont besoin de traiter de gros volumes de requêtes à moindre coût, comme la traduction, la classification ou le résumé de texte.
Mais ce n’est pas tout. Contrairement à ses prédécesseurs de la série « Flash », Flash-Lite est également un modèle raisonneur (ou thinking model), capable d’améliorer ses résultats s’il prend un peu plus de temps pour « réfléchir » avant de répondre. Et à la clé, les gains en précision sont loin d’être anecdotiques…
Un modèle pensé pour le volume… mais pas que
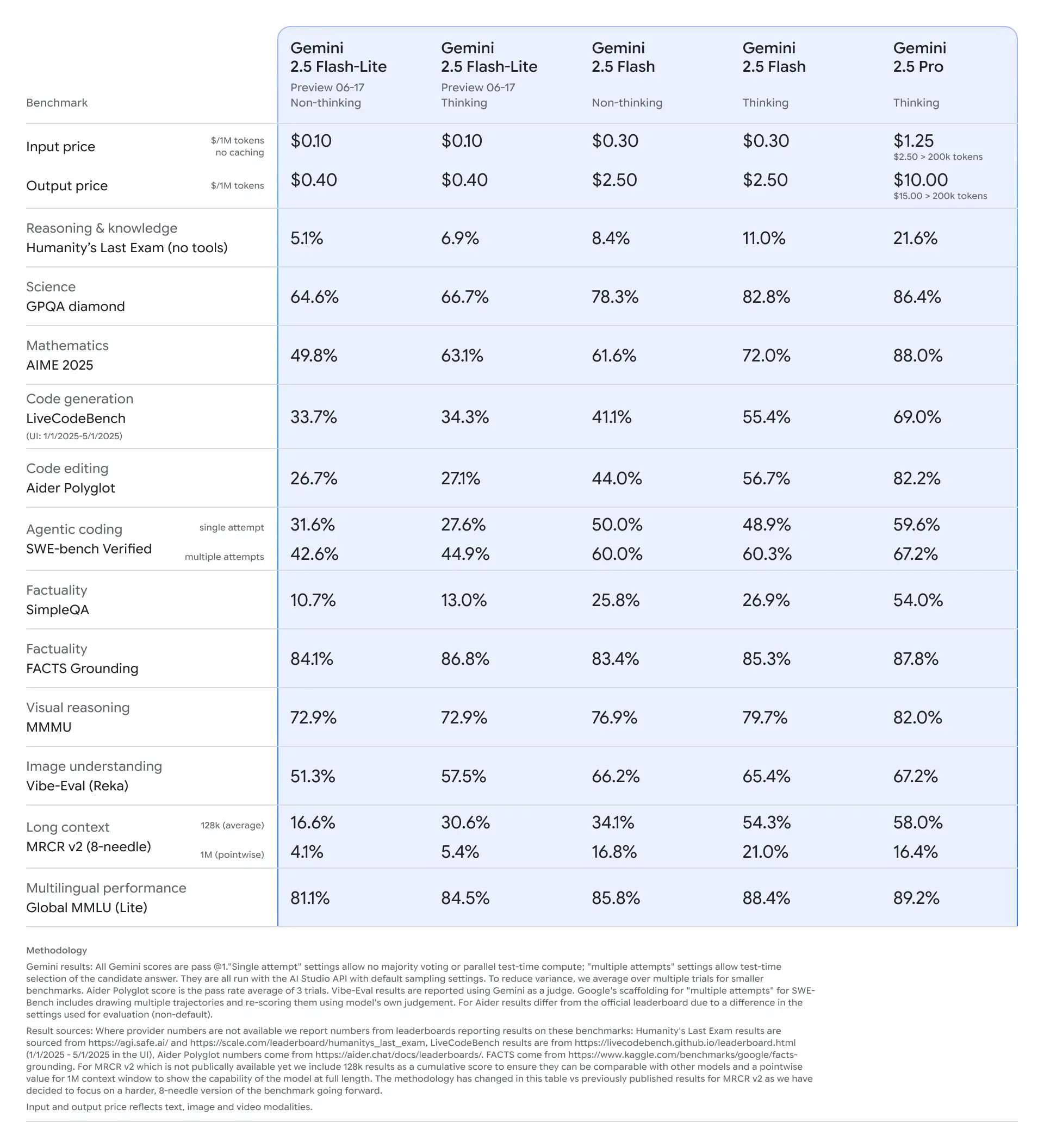
Sur le papier, Gemini 2.5 Flash-Lite est présenté comme le modèle le plus rapide et le plus économique de la famille 2.5. Il est facturé 0,10 $/million de tokens en entrée et 0,40 $/million de tokens en sortie, ce qui en fait une solution bien plus abordable que Flash (0,30 $/2,50 $) ou Pro (1,25 $/10 $). C’est aussi le seul modèle de la série où le mode « réflexion » (thinking) est désactivé par défaut, pour garantir une latence minimale.
Mais le vrai tour de force, c’est que même avec un budget réduit, Flash-Lite n’est pas limité à des tâches basiques. Grâce à son mode Thinking activable à la demande, il est capable de doubler ses performances sur certaines tâches complexes, comme les calculs mathématiques ou l’analyse de contexte sur de très longs textes.
Des résultats plus qu’honorables… surtout avec le mode Thinking activé
Même si Flash-Lite n’a pas vocation à rivaliser avec les modèles les plus puissants, il s’en sort plutôt bien dans les benchmarks. Et quand on active son mode Thinking, il fait mieux que certains modèles non raisonneurs bien plus chers. Voici quelques chiffres tirés des tests réalisés par Google :
- Raisonnement complexe (Humanity’s Last Exam) : → 5,1 % sans réflexion, mais 6,9 % avec le mode Thinking. Ce n’est pas énorme, mais c’est mieux que Gemini 2.0 Flash (5,1 %).
- Mathématiques (AIME 2025) : → de 49,8 % à 63,1 % en mode Thinking. À titre de comparaison, Flash plafonne à 61,6 % sans réflexion.
- Code (LiveCodeBench) : → passe de 33,7 % à 34,3 %, donc ici le gain est minime. Mais Flash-Lite reste devant la version 2.0 Flash (29,1 %).
- Compréhension d’image (Vibe-Eval) : → 51,3 % en mode standard, 57,5 % en Thinking.
- Multilingue (Global MMLU) : → 81,1 % sans réflexion, 84,5 % avec.
Sur quasiment tous les tests, Flash-Lite Thinking dépasse la version 2.0 Flash, tout en étant aussi rapide et bien moins cher.
À chaque besoin son modèle : Flash-Lite, Flash ou Pro ?
Pour éviter toute confusion, Google a pris le soin de repositionner clairement les trois modèles 2.5 actuellement disponibles. Chacun a sa spécialité, et il ne s’agit pas simplement de choisir « le plus cher donc le meilleur ».
- Gemini 2.5 Flash-Lite : Ultra rapide, économique, idéal pour les tâches en masse : génération de résumés, classification, traduction automatique, modération de contenu… Par défaut, il va droit au but, mais on peut activer le mode Thinking quand on a besoin de plus de finesse.
- Gemini 2.5 Flash : Un bon compromis entre vitesse et intelligence. Il est plus cher que Flash-Lite, mais aussi plus performant, surtout sur les tâches mixtes (langue, image, vidéo) ou les agents IA qui nécessitent un minimum de raisonnement. Le mode Thinking est toujours activé.
- Gemini 2.5 Pro : Le plus puissant et le plus cher. C’est le modèle à utiliser pour des cas complexes : génération de code avancée, compréhension de longs documents, agents autonomes, ou toute tâche nécessitant une précision maximale. C’est aussi celui qui est utilisé dans de nombreux outils pro et dev (Cursor, GitHub Copilot, Replit…).
Google propose même une grille de comparaison avec des niveaux de vitesse, performance, coût, et disponibilité, histoire de ne pas s’y perdre.
Un modèle en preview, mais déjà bien intégré
Gemini 2.5 Flash-Lite est pour l’instant proposé en preview, accessible depuis Google AI Studio et Vertex AI. Il rejoint les versions stables de Gemini 2.5 Flash et Pro, désormais disponibles pour une utilisation en production. Les trois modèles sont également intégrés dans l’application Gemini pour le grand public.
Google précise d’ailleurs que des variantes personnalisées de Flash-Lite et Flash sont déjà utilisées dans son moteur de recherche, preuve que ces modèles sont mûrs pour des cas d’usage à grande échelle.
Côté tarifs, Google a ajusté ses prix pour rendre l’offre plus lisible. Les différences entre modèles « Thinking » et « Non-thinking » ont été supprimées sur Flash. Flash-Lite, lui, garde cette option activable, ce qui permet de mieux maîtriser son budget selon les besoins. Enfin, Pro reste au top niveau… avec un prix qui va avec (jusqu’à 15 $ par million de tokens en sortie).
Source : Google





