Anthropic vient de sortir Claude Opus 4 et Claude Sonnet 4, deux nouveaux modèles d’intelligence artificielle qui envoient du lourd, surtout dans le domaine du développement logiciel. Sur les benchmarks, les résultats sont sans appel : ils font mieux que GPT-4.1, o3 ou encore Gemini 2.5 Pro.
Mais au-delà des chiffres, c’est toute la conception des modèles qui évolue. Raisonnement plus poussé, exécution d’outils en parallèle, meilleure mémoire… Anthropic veut clairement imposer Claude comme une référence, pas juste une alternative.
Deux modèles, deux usages… mais une ambition commune
Avec Claude Opus 4 et Claude Sonnet 4, Anthropic poursuit sa stratégie : proposer des modèles hybrides capables aussi bien de répondre instantanément que de prendre le temps de réfléchir quand c’est nécessaire.
Opus 4, c’est le haut de gamme. Il vise les usages complexes, les tâches longues, les workflows autonomes. De son côté, Sonnet 4 se veut plus léger, mais tout aussi performant sur des usages plus classiques. Et bonne nouvelle : il est accessible gratuitement, là où Opus 4 reste réservé aux offres payantes.
Les deux modèles partagent cependant le même moteur : une nouvelle génération d’IA taillée pour le développement, l’analyse de code, le raisonnement multi-étapes et l’utilisation parallèle d’outils. Concrètement, ils sont capables de :
- suivre des instructions complexes sans partir en freestyle,
- travailler sur de longues sessions en gardant le fil,
- et même alterner entre réflexion et exécution d’outils comme une vraie boîte à outils connectée.
Le code, leur terrain de jeu favori
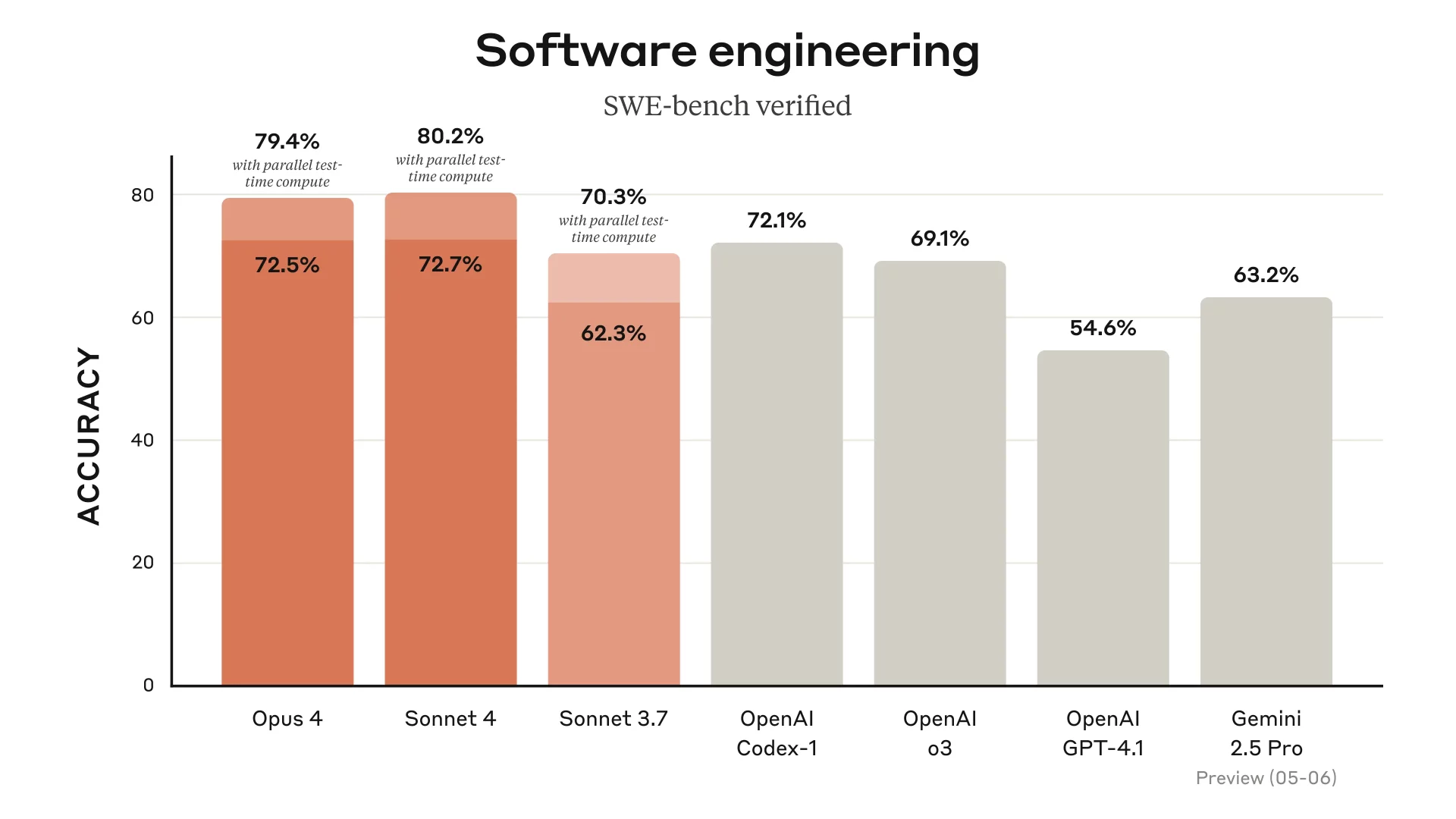
C’est sur les benchmarks de codage que Claude Opus 4 et Sonnet 4 écrasent vraiment la concurrence. Sur SWE-bench Verified, le test de référence pour évaluer les capacités réelles en ingénierie logicielle, Opus 4 atteint 72,5 % de réussite en conditions standard et jusqu’à 79,4 % avec calcul parallèle. Sonnet 4 n’est pas en reste, avec 72,7 % (ou 80,2 % en test parallèle), ce qui le place juste devant Opus 4 sur ce point précis.
Pour comparer :
- GPT-4.1 d’OpenAI plafonne à 54,6 %,
- Gemini 2.5 Pro de Google fait à peine mieux avec 63,2 %,
- même OpenAI o3, pourtant très bon en raisonnement, reste derrière avec 69,1 %.
Ces chiffres ne viennent pas d’un benchmark maison arrangé façon vitrine : SWE-bench est un test open source basé sur de vrais bugs corrigés dans de vrais projets GitHub. Il s’agit donc de tâches concrètes, pas de résolutions théoriques.
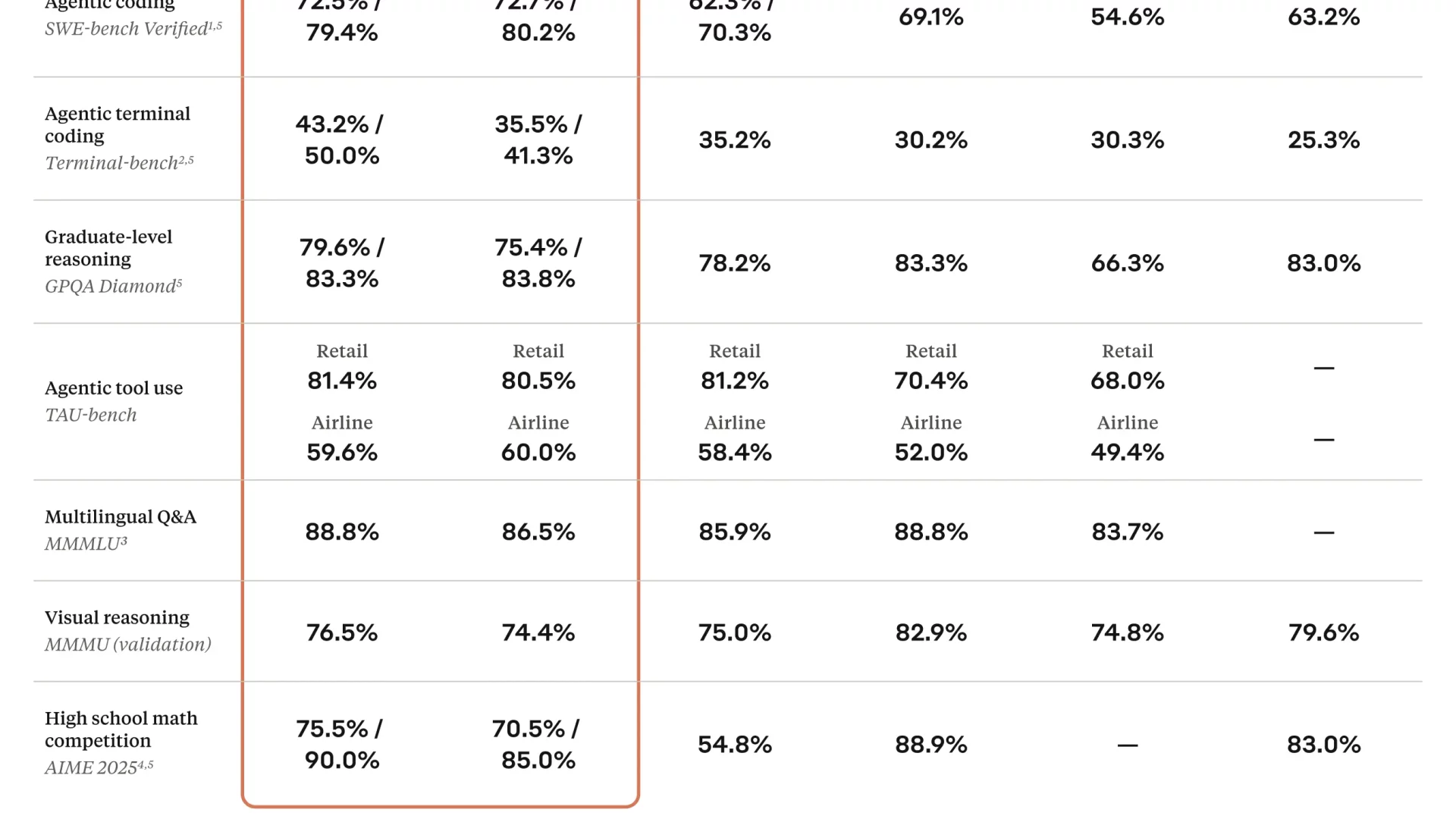
Et ce n’est pas juste une performance ponctuelle. Sur Terminal-bench, qui simule des scénarios en ligne de commande, Opus 4 atteint 43,2 %, loin devant GPT-4.1 (30,3 %) ou Gemini 2.5 Pro (25,3 %). On retrouve ici ce qui fait la force des modèles Claude : ils savent manipuler les outils, pas juste générer du texte qui sonne intelligent.
Raisonnement étendu, outils en parallèle et mémoire : Claude passe à la vitesse supérieure
Derrière les bons scores aux benchmarks, il y a surtout des capacités concrètes qui changent la donne pour les développeurs.
Les deux modèles Claude 4 introduisent ce qu’Anthropic appelle le « extended thinking » : un mode où le modèle prend plus de temps pour réfléchir avant de répondre. Utile quand il faut planifier, raisonner ou utiliser des outils externes. Ce raisonnement peut être combiné avec une exécution d’outils en parallèle, comme une recherche web ou l’analyse de fichiers, pour obtenir des résultats plus précis, mieux structurés.
Et ce n’est pas tout. Si on donne à Claude l’accès à des fichiers locaux, il est capable d’en extraire des faits importants, de les mémoriser et de les réutiliser plus tard. Par exemple, dans une session longue ou un projet complexe, il peut créer un guide de navigation, comme ici pendant une session Pokémon (véridique 👇) :
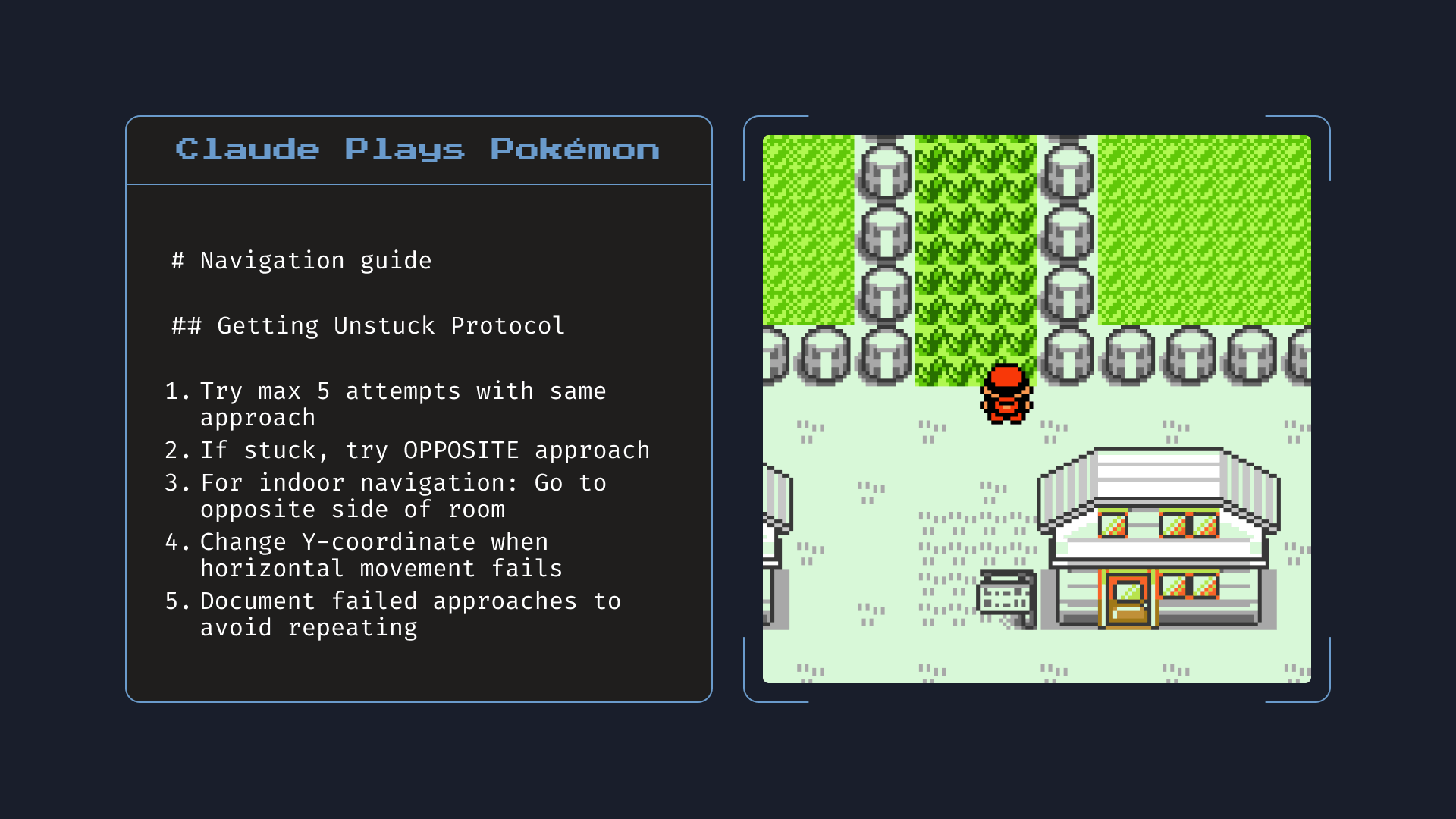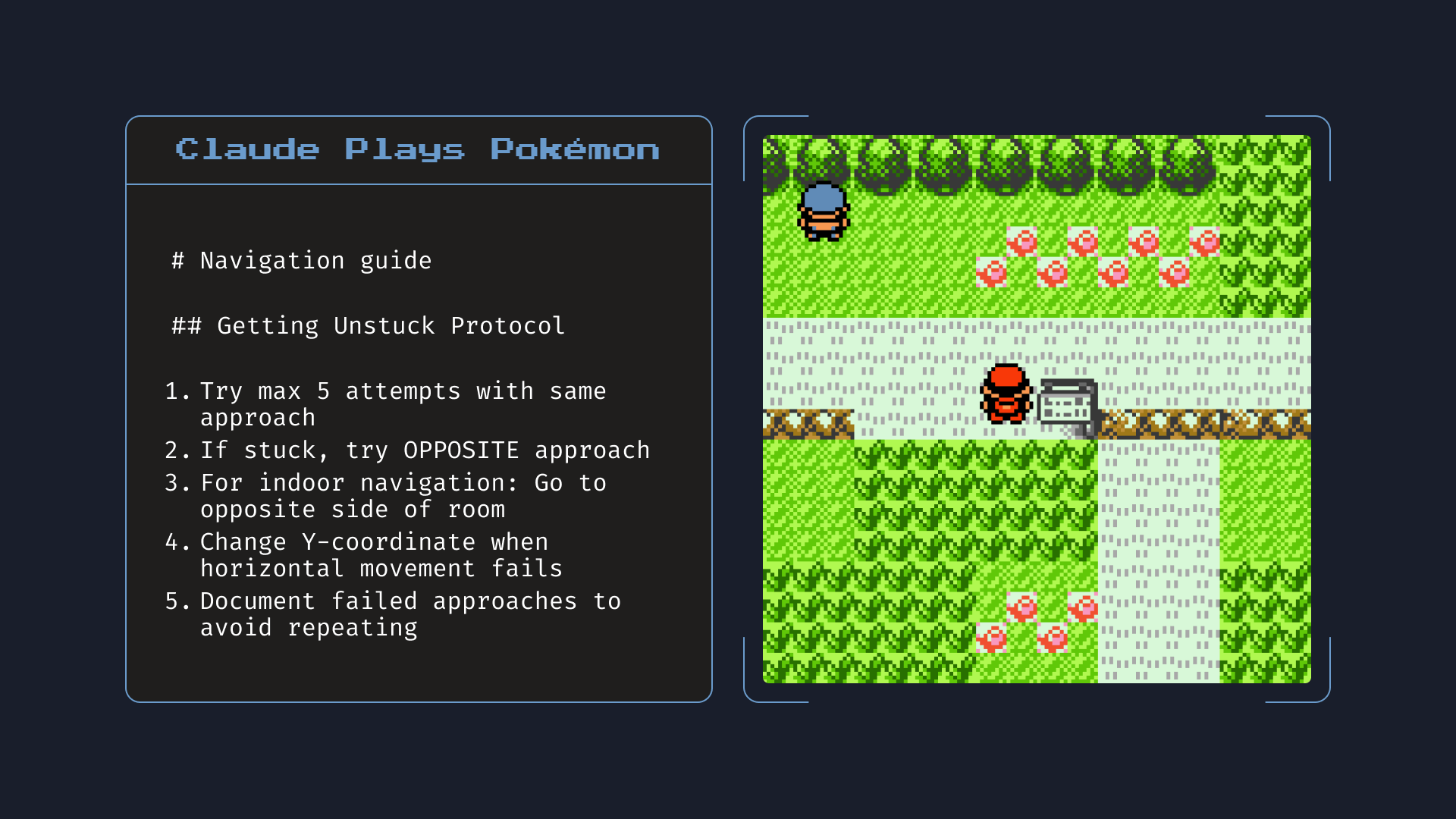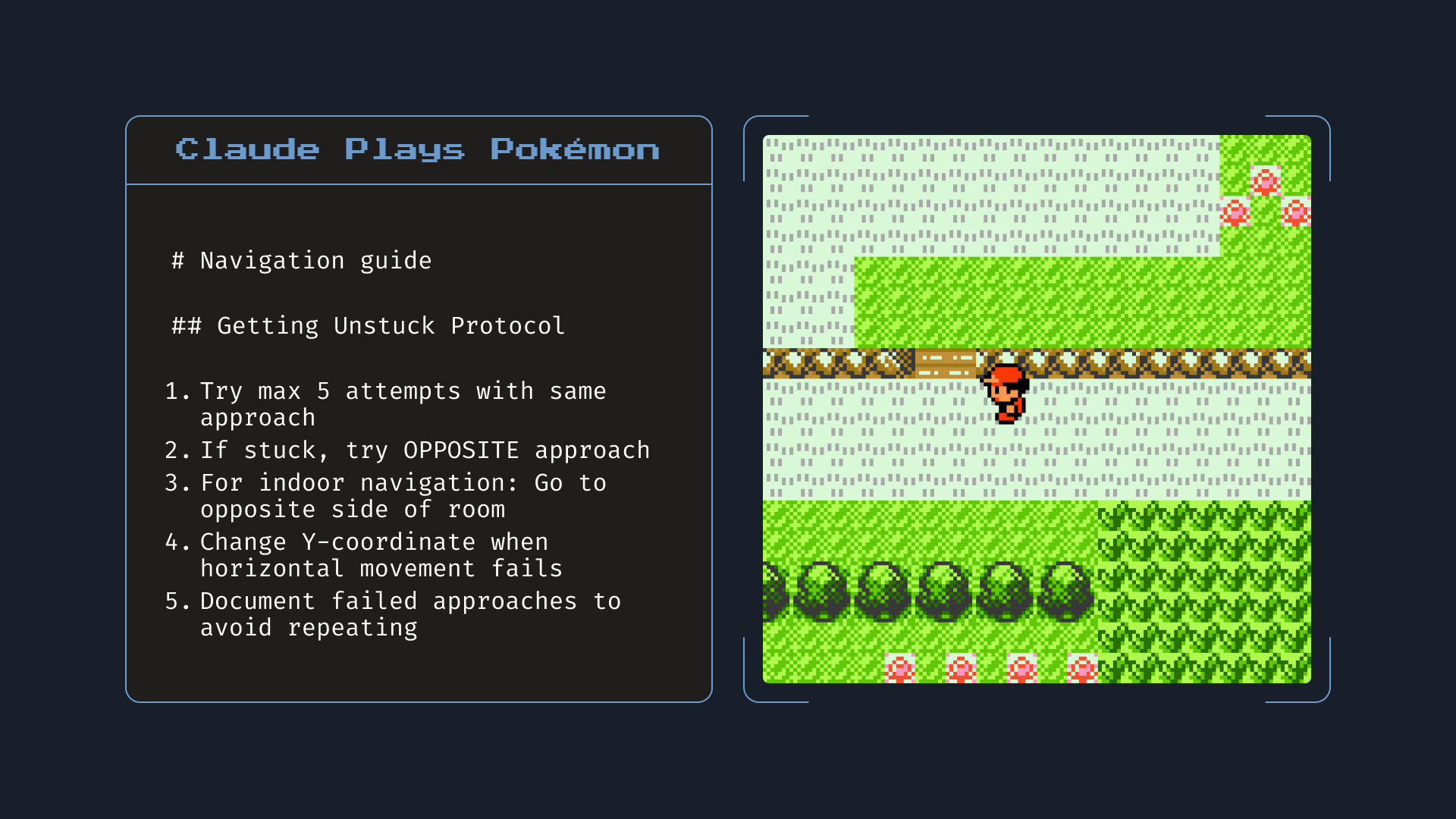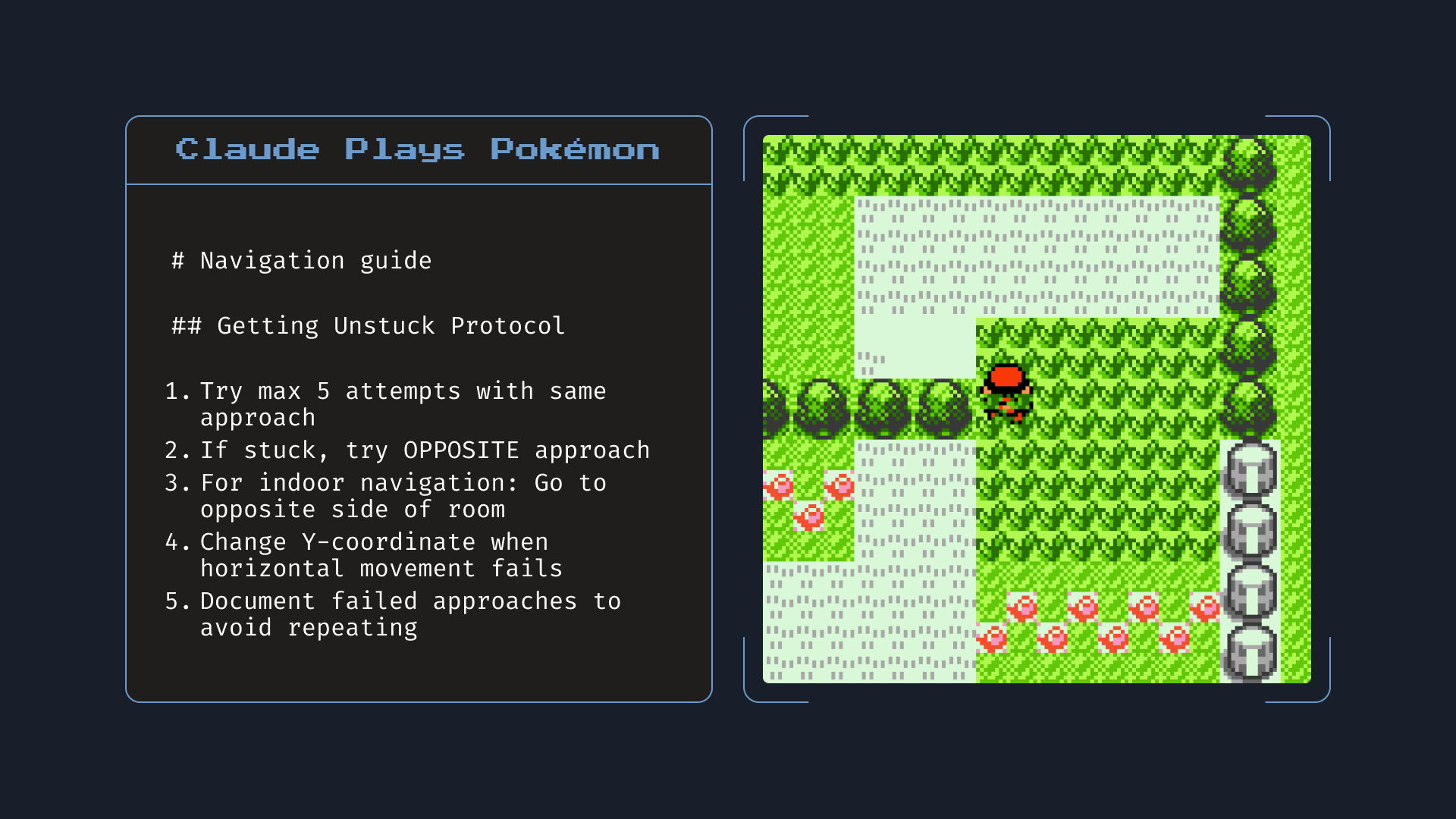
Cette capacité mémoire permet à Claude de ne pas repartir de zéro à chaque interaction. Il garde le fil, comprend ce qui a déjà été fait, et agit en conséquence. Un vrai plus pour le développement, mais aussi pour toutes les tâches structurées.
Claude Code : l’assistant de dev passe la seconde
En parallèle des nouveaux modèles, Anthropic officialise aussi Claude Code, son outil en ligne de commande pensé pour les développeurs. Déjà testé en avant-première, il devient maintenant accessible à tous, avec plusieurs nouveautés bien senties.
Ce petit assistant peut :
- exécuter des tâches en arrière-plan via GitHub Actions,
- s’intégrer nativement à VS Code ou JetBrains,
- proposer des suggestions de code directement dans vos fichiers,
- et même être connecté à vos propres projets via un SDK extensible.
L’objectif est de faire de Claude un vrai partenaire de développement, capable de répondre, corriger, réagir à vos pull requests ou à vos tests qui plantent. Et pour voir tout ça en action, rien de mieux qu’un petit aperçu vidéo 👇
Accès, tarifs et compatibilité : qui peut utiliser quoi ?
Si vous avez envie de tester ces modèles, bonne nouvelle : Claude Sonnet 4 est dispo gratuitement pour tous les utilisateurs de Claude. Vous pouvez y accéder directement via l’interface web ou l’utiliser via l’API d’Anthropic, Amazon Bedrock ou Google Vertex AI.
Pour Claude Opus 4, en revanche, il faudra passer par une formule payante (Pro, Max, Team ou Enterprise). Et niveau tarifs, pas de surprise, Anthropic conserve les mêmes prix que pour la génération précédente :
- Opus 4 : 15 $ par million de tokens en entrée, 75 $ en sortie
- Sonnet 4 : 3 $ en entrée, 15 $ en sortie
À noter que les deux modèles incluent les nouvelles options comme le raisonnement étendu et l’utilisation d’outils, mais seuls les abonnés y ont pleinement accès.
Et pour voir à quoi ressemble une journée avec Claude quand on l’utilise dans tous ses usages (pas seulement pour coder), Anthropic a publié une vidéo assez parlante :
Des cas concrets qui parlent
Anthropic n’a pas lancé ses modèles les mains dans les poches. Plusieurs partenaires ont déjà testé Opus 4 et Sonnet 4 sur des projets bien réels… et les retours sont plutôt impressionnants.
- Rakuten a fait tourner Claude Opus 4 pendant 7 heures d’affilée sur une tâche complexe de refactorisation open source, sans intervention humaine. Une autonomie totale, sur plusieurs centaines d’étapes, le tout avec un résultat stable.
- GitHub a carrément décidé d’intégrer Claude Sonnet 4 comme nouveau modèle par défaut dans GitHub Copilot. C’est un gros signal : la plateforme mise sur sa précision et ses performances en codage pour remplacer GPT-4.
- Sourcegraph note que Claude Sonnet 4 suit mieux les consignes, reste plus longtemps dans le contexte et améliore la qualité du code généré, notamment pour les grosses bases de code. Bref, il ne fait pas que générer du code au kilomètre, il comprend ce qu’il fait.
- Cursor, Replit, Block, Augment Code… tous rapportent des progrès dans la navigation, la compréhension du code et même dans les suggestions esthétiques ou les modifications chirurgicales.
Ces cas d’usage confirment ce qu’on pressentait déjà : avec cette version 4, Claude franchit un cap et devient un véritable outil de production, pas juste un chatbot doué.
En résumé
Avec Claude Opus 4 et Sonnet 4, Anthropic ne cherche pas à impressionner avec des effets d’annonce : les résultats sont là, aussi bien sur les benchmarks que dans les usages concrets. Entre performances de haut niveau, raisonnement amélioré, intégrations poussées avec les outils de développement et mémoire étendue, les deux modèles posent une vraie alternative crédible aux poids lourds comme GPT-4.1 ou Gemini 2.5 Pro.
Opus 4 s’impose comme une bête de course pour les tâches longues et complexes, tandis que Sonnet 4 trouve naturellement sa place dans un usage quotidien, plus fluide, mais toujours performant, et surtout, accessible gratuitement, ce qui ne gâche rien.
Reste à voir comment OpenAI et Google vont répondre… mais une chose est sûre : Claude est désormais un acteur central de l’IA et pas seulement un outsider prometteur.
Source : Anthropic